I recently had the pleasure of installing a Lisp-Environment on Windows. It is not immediately obvious how to do this best. Basically my options boiled down to using native CLISP and Emacs or the Cygwin-Version or a combination thereof.
After I was done (of course :-) ), I found Lisp Cabinet - several Lisps bundled with Emacs/SLIME. Even ASDF works!
Wednesday, May 25, 2011
Wow! I used a function from Oracle 11g R2!
As a developer that uses the database to just store and retrieve things, I was until recently of the opinion that no interesting features had entered the Oracle database from Release 9i R2 on. Heck, even the sophisticated OO-features were available in 8i!
But now I had do compile a report where values from several rows had to be concatenated with semicolons as delimiters. I did not want to do this PL/SQL (seemed to me like overkill, with loops and all). Luckily, I found the funtion listagg, which does exactly that: Listagg-Documentation from Oracle.
Here is an example that uses listagg to give a report of all Orders (one Order per line) with all attached short-texts seperated by semicolons in the column "short_texts".
So, from time to time, I will actually look for new features in Oracle DB!
But now I had do compile a report where values from several rows had to be concatenated with semicolons as delimiters. I did not want to do this PL/SQL (seemed to me like overkill, with loops and all). Luckily, I found the funtion listagg, which does exactly that: Listagg-Documentation from Oracle.
Here is an example that uses listagg to give a report of all Orders (one Order per line) with all attached short-texts seperated by semicolons in the column "short_texts".
selectIn reality, you will have to restrict this query to just a few Orders - unless you are willing to wait for a long time....
fadf.pk1_value as oe_header_id, listagg(fdst.short_text,';') within group (order by fadf.seq_num) as short_texts
from fnd_documents_short_text fdst
join fnd_attached_docs_form_vl fadf on (fadf.function_name='OEXOEORD' and fdst.media_id=fadf.media_id)
join fnd_documents fd on (fd.document_id = fadf.document_id) group by fadf.pk1_value;
So, from time to time, I will actually look for new features in Oracle DB!
Tuesday, January 25, 2011
SQLPlus-Mode for Emacs
Recently I had to get some data from the Oracle E-Business Suite and it turned out that I needed some more or less complex SQL to accomplish the task. When I was nearly finished, Oracle SQLDeveloper crashed. Boom - all was gone. I was very angry. Being an Emacs-fan, I thought how difficult it would be to have some basic functionality in Emacs. The features I wanted were just 1) Edit SQL in a buffer, 2) send this SQL to SQLPlus and 3) view the output nicely formatted in another buffer.
I knew I could start SQLPlus in a shell-buffer, but the output from a select would look just like so:
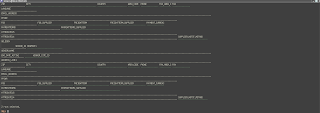
Hm. Not very useful. How can one tell SQLPlus to use just the minimum space for each column? One can't. Each column must be tailored individually.
Then I looked at several Emacs-modes out there for SQLPlus. Most of them did not install right away or screwed up based on my data (OK, data from the Oracle EBS is insane - you would not see tables with so many columns anywhere else - but still it is perfectly legal). I tried to fix the problems, but could not - the elisp-code was just too much for me. Damn it, most of these modes try to emulate whole IDEs!
So, that was not what I wanted. So I rolled my own. The result is quite usable for me. Here is a screen-shot:
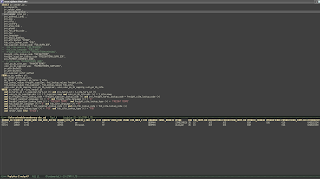
In the buffer above you can enter SQL and send it with Ctrl-Enter (anywhere in the paragraph) to SQLPlus, the result appears nicely formatted in the lower buffer. When you first type Ctrl-Enter, a buffer appears in which you have to start SQLPLus and log on to Oracle. sqlplus-2-mode interacts with this buffer behind the scenes. Results from SQLPlus are displayed in the buffer *sqlplus-2-output*. Only the first few rows (this is configurable) are displayed - after all, this is not a reporting-tool.
Now, I can concentrate on the SQL and fear no more crashes - finally!
You can get the mode here. I assume that you know how to set up an emacs-mode, so I will not explain it here. There are still a few problems to be solved (long-running statements are not handled well) - once that is solved, I will write end-user-friendly documentation. Right now it is just a quick hack :-)
I knew I could start SQLPlus in a shell-buffer, but the output from a select would look just like so:

Hm. Not very useful. How can one tell SQLPlus to use just the minimum space for each column? One can't. Each column must be tailored individually.
Then I looked at several Emacs-modes out there for SQLPlus. Most of them did not install right away or screwed up based on my data (OK, data from the Oracle EBS is insane - you would not see tables with so many columns anywhere else - but still it is perfectly legal). I tried to fix the problems, but could not - the elisp-code was just too much for me. Damn it, most of these modes try to emulate whole IDEs!
So, that was not what I wanted. So I rolled my own. The result is quite usable for me. Here is a screen-shot:

In the buffer above you can enter SQL and send it with Ctrl-Enter (anywhere in the paragraph) to SQLPlus, the result appears nicely formatted in the lower buffer. When you first type Ctrl-Enter, a buffer appears in which you have to start SQLPLus and log on to Oracle. sqlplus-2-mode interacts with this buffer behind the scenes. Results from SQLPlus are displayed in the buffer *sqlplus-2-output*. Only the first few rows (this is configurable) are displayed - after all, this is not a reporting-tool.
Now, I can concentrate on the SQL and fear no more crashes - finally!
You can get the mode here. I assume that you know how to set up an emacs-mode, so I will not explain it here. There are still a few problems to be solved (long-running statements are not handled well) - once that is solved, I will write end-user-friendly documentation. Right now it is just a quick hack :-)
Sunday, January 9, 2011
Minimalistic-ETL with clojure
Suppose you are faced with the task to transfer data from one system to another.
Now, suppose that these systems are SQL-friendly and have JDBC-Drivers available. This is still the case in many "enterprise"-environments. The preferred way of interacting with these systems is through interfaces tables or stored procedures.
I know that in theory, everything should/could be done with web-services, but in reality (2010!), just SQL is used most of the time (that is only my limited experience, of course...).
So, if you want to transfer data from system A to system B, you are selecting from some table in A and are inserting into some table from B. Sounds easy, right? Well, so I thought. I did some research on products for enterprise-integration, and it was not easy to find a tool which is capable of doing just that. Instead, you are faced with "solutions" that talk all the time about BPEL, BPMN, SOA and all that, and it is hard to imagine how these tools would help getting this simple job done. I will compare the solution developed here to a well-known enterprise tool at the end of this post.
Then I stumbled upon Scriptella, which seemed ridiculously simple.
Its inventor created a simple DSL for this job; it looks like this:
<query connection-id="in">
SELECT * from Bug
<script connection-id="out">
INSERT INTO Bug VALUES (?ID, ?priority, ?summary, ?status);
</script>
</query>
Looks extremely simple. We have an outer block named query where the select from the source table resides, and an inner block named script, where can insert into our target table and use variables from the source table.
Now I thougt "Hm, that is actually all I need in my project, but can I do it with clojure?" The
answer is yes, and it takes only a few lines to implement such a DSL!
Writing the DSL
Let's write this DSL. What language elements do I need? Three things:
- A syntax for specifying the connections
- A syntax for specifying the query from the source table
- A syntax for inserting values in the target table
(defn connect
"Creates a JDBC-Connection according to def"
[def]
(clojure.contrib.sql.internal/get-connection def))
We can use it like so:
(def source-def {:classname "oracle.jdbc.driver.OracleDriver"
:subprotocol "oracle:thin"
:subname "@localhost:1521:xe"
:user "scott"
:password "tiger" })
(def source (connect source-def))
Now we have a connection for the source. We do a similar thing for the target. Let's assume we have done this and bind the connection to target:
(def target (connect target-def))
Now for the second part, defining a syntax for the query. This will be a macro that takes the connection, the query string and a body of code as arguments. It will then provide the body with a binding *rs* which is set to the sequence of resultsets from the query:
(defmacro with-query-results
"Executes query on connection and evaluates body with *rs* bound to the result of
resultset-seq executed on the result-set."
[con query body]
`(with-open [stmt# (.prepareStatement ~con ~query)]
(with-open [rset# (.executeQuery stmt#)]
(doseq [~'*rs* (resultset-seq rset#)]
~body))))
Now for the final part, the insert into the target table. This is again a macro which takes as parameters the connection, the SQL for the insert and the parameters for the insert. It will then execute the SQL with the given parameters. I also added some code for logging so that the user can figure out where the error, if any, happened:
(defmacro sql
[con sql sql-params]
`(do
(let [whole-sql-for-logging# (str "SQL: " ~sql ":" ~sql-params)]
(clojure.contrib.logging/debug whole-sql-for-logging#)
(try
(with-open [stmt# (.prepareStatement ~con ~sql)]
(doseq [[index# value#] (map vector (iterate inc 1) ~sql-params)]
(.setObject stmt# index# value#))
(.executeQuery stmt#))
(catch Exception e#
(do
(clojure.contrib.logging/error whole-sql-for-logging# e#)
(throw e#)))))))
One more utility macro for accessing variables from with-query-results:
(defmacro v?and that's it!
"Returns the value of the column t"
[t]
`(~(keyword t) ~'*rs*))
The DSL in Action
Now let us see this in action:
(with-query-results source "select * from emp"This select everything from the emp table and fills a fictional table employees_names with just the names. Columns from the source table are accessed with the function we defined above: (v? column-name).
(sql target "insert into employees_names (name) values (?)" [(v? ename)]))
And now for the fun-part. The first goodie is about memory consumtion. The resultset-sequence from with-query-results is lazy. This means that this simple program does not store the whole result from the query into memory in order to insert it into the target table. Instead, the results are fetched as needed, just when they are accessed. This saves a lot of memory and implies that there is no limit to the size of the table whose data is transferred.
The second is about data-transformation. In the above code, (v? name) is just plain clojure-code, and we have the full power of the language available! If we wanted only upper-case names in the target table, we could simply type (.toUpperCase (v? ename)) instead. This is possible because we used macros above.
What about DVMs (Domain-Value-Maps)? Just as easy. Say you have a system called A where boolean values are represented by "Y" and "N" and in system B these are represented by "J" and "N". So you want to translate "Y" to "J" and "N" to "N". Define a function
(defn apply-dvmThen define the DVM itself:
"Domain-Value-Map. Usage:
(apply-dvm the-dvm-map :system-a :system-b 'Y')"
[dvm from to txt]
(let [res (filter #(= txt (from %)) dvm)]
(cond
(= 0 (count res)) (throwf "No match: DVM=%s, From=%s, Text=%s" dvm from txt)
(> 1 (count res)) (throwf "More than one match: DVM=%s, From=%s, Text=%s" dvm from txt)
true (to (first res)))))
(def dvm-boolNow to use the DVM you just type (apply-dvm dvm-bool (v? my-Y-N-column)).
[{:system-a "Y" :system-b "J"}
{:system-a "N" :system-b "N"}])
Summary
We have written a little bit of clojure code that allows us to perform complex etl jobs.
Why was that so simple? After all, there are many etl-tools on the market, that are itself immensely complex. It is unbelievable that so little code can perfom equivalent jobs. Why is this so?
My explanation is that these tools invent new languages that are artificially restricted to accomplish this task. Most likely, the payload from the database will be transformed to XML in proprietary fashion you will code the interesting stuff in XSLT, and the resulting XML will be fed into the target database, again in a proprietary fashion. In addition you have to provide BPEL-Code to "orchestrate" the integration-flow. And then you will have to provide some glue configuration that keeps all of this together. Some tools even talk with Webservices internally, exposing you to the complexities of that technology too. All of these introduce artificial breaks in your code. I have tried to accomplish the above task with some state-of-the-art software. And believe me: There are a lot of things that can go wrong with this configuration, and you can spend hours and hours to fix problems that do not have anything to do with your original problem, which is just to transfer some data. This is because you constantly have to switch between SQL, proprietary database-adapter configuration, XML, XSLT, BPEL, WSDL (if you are extremely unlucky), and lots of glue-configuration.
Now it is time to take a step back. If all you want to achive is just transferring data from table to table, you will NOT need all of this. After all, it is just selecting from a table, doing some transformations and then inserting into another table.
How complex do you want to make this?
With the above solution, you are actually doing all of your coding in ONE language, clojure. This would not have been possible in a language without a real macro-system. With such a language, there is no need to use an artificially restricted language, but you can use full clojure everywhere - there is no need switch between different technologies, and this allows you to keep focus on the real task without wasting time to make your tools happy.
This is where productivity comes from.
Friday, February 12, 2010
How to integrate JasperServer and Oracle E-Business Suite
Suppose you want to use JasperServer (3.7) to generate reports containing data from the E-Business Suite. (In case you wonder, JasperServer is an open-source product that can be used to host JasperReports reports).
In many cases you will just write a (huge) select statement that extracts the data. However, sometimes the data will have to come from an Oracle API, and in that case we can do something like
However, many of Oracle's APIs require some initialization first, which is done with the familiar function
While it is still possible to include the call to fnd_global.apps_initialize in some function that you later 'select from dual' from, there is a caveat: You are likely to run into the error
ORA-14552: cannot perform a DDL, commit or rollback inside a query or DML
This is should not be surprising, there is nothing to stop Oracle from doing commits and the like in fnd_global.apps_initialize. They might write audit-logs, or it might be something completely different. We do not know.
So we need to be able to issue a PL/SQL Statement before the select in JasperServer.
Luckily this is possible by using the language 'plsql' in queryString:
in the jrxml file.
This enables us to write stored procedures that can do all kinds of fancy PL/SQL-Stuff and then return a cursor with the desired query results.
In order to be able to do this, some extra configuration is needed.
First, you need to add the line
to the file
You also have to add the string 'plsql' below 'sql' in the files (war-file-for-jasperserver)/WEB-INF/flows/queryBeans.xml
and (war-file-for-jasperserver)/WEB-INF/applicationContext.xml
Now you can write a PL/SQL-Procedure like the following:
You have to define 'type ref_cur is ref cursor;' in your package spec.
Now you can use this procedure in the jrxml like so:
I also had to add
in that file.
A nice side-effect is that the messy SQL is kept out of the jrxml.
In many cases you will just write a (huge) select statement that extracts the data. However, sometimes the data will have to come from an Oracle API, and in that case we can do something like
select some_oracle_function(x) from dual;However, many of Oracle's APIs require some initialization first, which is done with the familiar function
fnd_global.apps_initialize.While it is still possible to include the call to fnd_global.apps_initialize in some function that you later 'select from dual' from, there is a caveat: You are likely to run into the error
ORA-14552: cannot perform a DDL, commit or rollback inside a query or DML
This is should not be surprising, there is nothing to stop Oracle from doing commits and the like in fnd_global.apps_initialize. They might write audit-logs, or it might be something completely different. We do not know.
So we need to be able to issue a PL/SQL Statement before the select in JasperServer.
Luckily this is possible by using the language 'plsql' in queryString:
<querystring language="plsql">...
in the jrxml file.
This enables us to write stored procedures that can do all kinds of fancy PL/SQL-Stuff and then return a cursor with the desired query results.
In order to be able to do this, some extra configuration is needed.
First, you need to add the line
net.sf.jasperreports.query.executer.factory.plsql=com.jaspersoft.jrx.query.PlSqlQueryExecuterFactory
to the file
(war-file-for-jasperserver)/WEB-INF/classes/jasperreports.propertiesYou also have to add the string 'plsql' below 'sql' in the files (war-file-for-jasperserver)/WEB-INF/flows/queryBeans.xml
and (war-file-for-jasperserver)/WEB-INF/applicationContext.xml
Now you can write a PL/SQL-Procedure like the following:
procedure get_data_from_ebs(p_cursor out ref_cur, p_some_parameter in number) is
begin
fnd_global.apps_initialize(-1,-1,-1);
open p_cursor for
select * from some_table where p_some_parameter=xyz;
end;
You have to define 'type ref_cur is ref cursor;' in your package spec.
Now you can use this procedure in the jrxml like so:
<querystring language="plsql">
<![CDATA[{call get_data_from_ebs($P{cursor}, $P{some_parameter})}]]>
</querystring>
I also had to add
<parameter name="DATABASE_TIMEZONE" class="java.lang.String" isforprompting="false">
<defaultvalueexpression><![CDATA["Europe/Berlin"]]></defaultvalueexpression>
</parameter>
in that file.
A nice side-effect is that the messy SQL is kept out of the jrxml.
Friday, November 20, 2009
How to get the Status of an Invoice
select APPS.Ap_Invoices_Pkg.GET_APPROVAL_STATUS(I.INVOICE_ID, I.INVOICE_AMOUNT,I.PAYMENT_STATUS_FLAG,I.INVOICE_TYPE_LOOKUP_CODE) FROM AP_INVOICES_ALL I where i.invoice_id='id of the invoice';
You have to set the Org-Id before you do that. This can be done with
call fnd_client_info.set_org_context('
How to get the invoice(s) corresponding to a PO
select i.invoice_num from ap_invoices_all i, ap_invoice_distributions_all aid, po_distributions_all pd, po_headers_all ph
where i.invoice_id = aid.invoice_id
and aid.po_distribution_id = pd.po_distribution_id
and pd.po_header_id=ph.po_header_id
and ph.segment1='Your PO-Number;
where i.invoice_id = aid.invoice_id
and aid.po_distribution_id = pd.po_distribution_id
and pd.po_header_id=ph.po_header_id
and ph.segment1='Your PO-Number;
Subscribe to:
Comments (Atom)